반응형
해당 포스팅은 'Learn Prompting' 블로그 내용을 학습하며 요약한 글로
정확한 내용은 하단의 링크를 이용해 본문을 확인하시길 바랍니다.
LLM의 한계점
- LLM은 매우 강력하지만 사용할 때 주의해야 할 한계점이 많이 존재
1. 인용(Citing Sources)
- LLM은 대부분 소스를 정확하게 인용할 수 없음
- 인터넷에 접속할 수 없고 정보가 어디에서 왔는지 정확히 기억하지 못하기 때문
- 좋아 보이지만 완전히 부정확한 소스를 생성하는 경우가 많음
- 이 문제는 검색 증강 LLM(인터넷 및 기타 소스를 검색할 수 있는 LLM)을 사용하면 어느정도 해결할 수 있음
2. 편향(Bias)
- LLM은 종종 편향된 결과를 생성할 수 있음
- 안전요원이 있어도 가끔 성차별/인종차별/동성애혐오적인 말을 함
- 소비자가 사용하는 애플리케이션에서 LLM을 사용할 때 또는 연구에 사용할 때 주의 필요
3. 거짓(Hallucinations)
- LLM은 답변을 모르는 질문을 받았을 때 거짓을 자주 생성함
- 답을 모른다고 말할 때도 있지만 대부분의 경우 자신 있게 잘못된 대답을 함
4. 수학(Math)
- LLM은 종종 수학을 잘 못함
- 이 문제는 Tool Augmented LLM을 사용하여 어느 정도 해결할 수 있음
5. 프롬프트 해킹(Prompt Hacking)
- 사용자는 종종 LLM을 속여 원하는 콘텐츠를 생성할 수 있음
LLM 설정
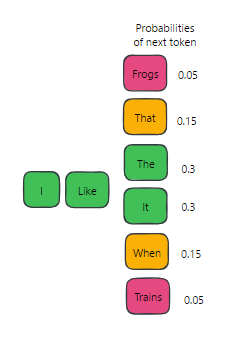
- LLM의 output은 다양한 측면을 제어하는 하이퍼파라미터의 영향을 받을 수 있음
- 하이퍼파라미터를 조정하여 보다 창의적이고 다양하며 흥미로운 결과를 생성할 수 있음
- 대표적으로 Temperature, Top p등이 있음
- 학습률, 레이어 수, 은닉 크기 등과 같은 일반 하이퍼파라미터와 다름
Temperature(온도)
- 언어 모델의 임의성을 제어하는 하이퍼파라미터
- 높은 온도는 보다 예측 불가능하고 창의적인 결과를, 낮은 온도는 보다 일반적이고 보수적인 결과를 생성
- ex. 모델의 온도를 1.0에서 0.5로 설정하는 경우, 보다 더 예측 가능하고 덜 창의적인 텍스트를 생성
Top p
- 언어 모델의 무작위성을 제어하는 하이퍼파라미터
- 임계 확률 설정 -> 누적 확률이 임계 값을 초과하는 상위 토큰 선택 -> 토큰 집합에서 무작위로 샘플링하여 output 생성
- 이 방법은 전체 어휘를 무작위로 샘플링하는 기존 방법보다 더 다양하고 흥미로운 결과를 생성할 수 있음
- ex. 상위 p를 0.9로 설정하면 모델은 확률 질량의 90%를 구성하는 가장 가능성이 높은 단어만 고려
그 외 관련 하이퍼파라미터
- 빈도(frequency), 존재(presence) 패널티 등과 같이 언어 모델 성능에 영향을 줄 수 있는 다른 많은 하이퍼 매개변수가 존재
하이퍼파라미터가 모델에 미치는 영향
- 온도와 top p는 모두 생성된 텍스트의 무작위성과 다양성 정도를 제어하여 언어 모델의 출력에 영향을 줄 수 있음
- 높은 온도 또는 높은 p 값은 더 예측할 수 없고 흥미로운 결과를 생성하지만 오류 또는 무의미한 텍스트의 가능성도 증가시킴
- 텍스트 생성 작업 중 창의로운 결과가 필요한 경우 사용할 수 있음
- 낮은 온도 또는 낮은 p 값은 보다 보수적이고 예측 가능한 결과를 생성할 수 있지만 반복적이거나 흥미롭지 않은 텍스트가 될 수 있음
- 번역 작업이나 질문 답변과 같이 정확성이 중요한 작업의 경우 낮은 온도 또는 최고 p 값을 사용해야 함
- 높은 온도 또는 높은 p 값은 더 예측할 수 없고 흥미로운 결과를 생성하지만 오류 또는 무의미한 텍스트의 가능성도 증가시킴
- 하이퍼파라미터와 모델 출력 간의 관계를 이해하면 특정 작업 및 애플리케이션에 대한 프롬프트를 최적화할 수 있음
- ChatGPT와 같은 일부 모델에서는 하이퍼파라미터를 조정할 수 없음
반응형