Transformer
Transformer는 RNN 언어 모델에서부터 시작었다.
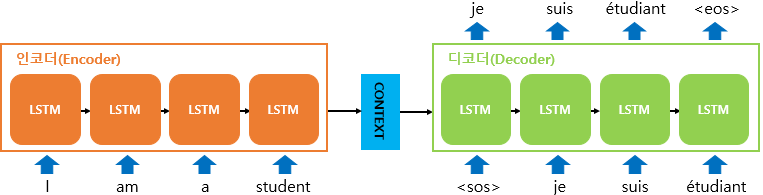
기존의 RNN은 하나의 고정된 크기의 벡터(Context vector)에 모든 정보를 압축하므로 정보 손실이 발생하며 순차적 입력 구조 때문에 먼저 입력된 단어의 정보가 잘 반영되지 않는(Vanishing gradient) 단점이 존재한다.
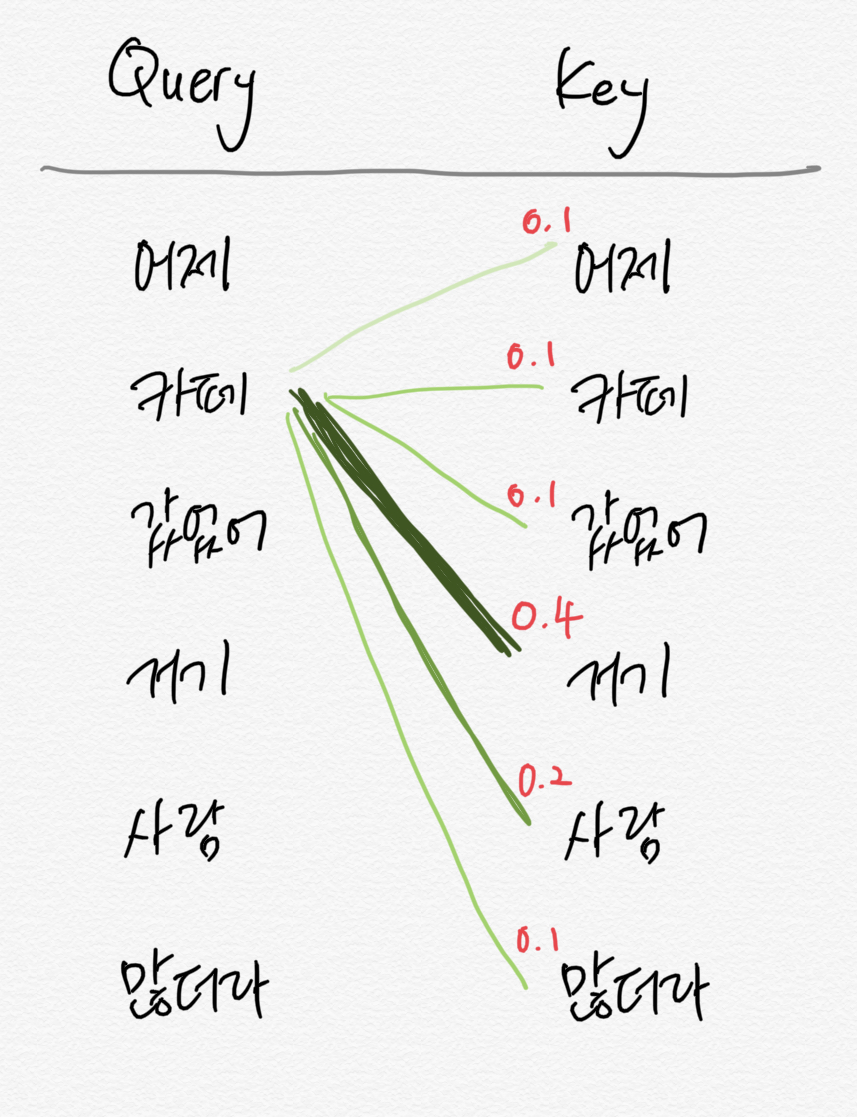
이를 보정해주기 위한 어텐션(Attention) 기법이 등장했지만, 순차적 입력 구조는 그대로이므로 성능 개선에 한계가 있다.
어텐션은 입력 문장 내의 단어들끼리 유사도를 구함으로써 특정 단어와 연관된 확률이 높은 단어를 찾으므로 RNN의 정보 손실 문제를 해결할 수 있다.
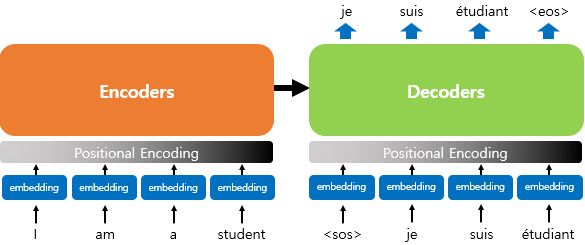
트랜스포머는 각 단어의 임베딩 벡터에 위치 정보들을 더하여 모델의 입력으로 사용(Positional encoding)하므로 RNN처럼 단어를 순차적으로 입력하지 않아도 되어, Self-attention이 가능하다.
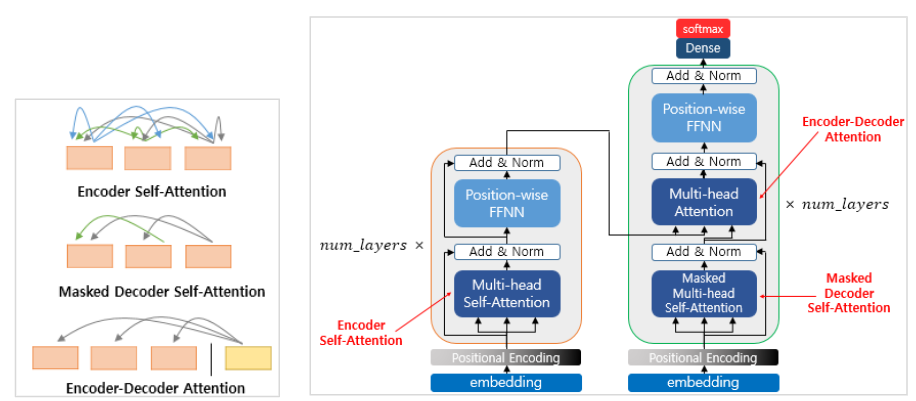
이 Self-attention 알고리즘이 사용된 모델을 일반적으로 Transformer라 한다.
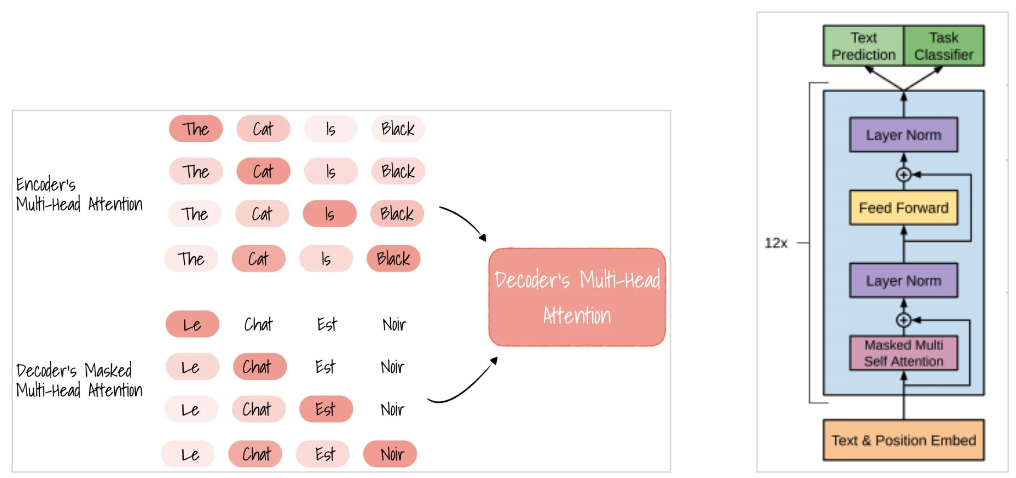
GPT는 인코더-디코더 구조의 트랜스포머에서 디코더만 사용한다. 디코더는 대상 단어 앞의 단어만 Attention에 참고하여 뒷 단어를 예측하므로 텍스트 생성 Task에 더 강하다.
Reference
https://www.youtube.com/watch?v=mxGCEWOxfe8
https://jalammar.github.io/illustrated-transformer/
The Illustrated Transformer
Discussions: Hacker News (65 points, 4 comments), Reddit r/MachineLearning (29 points, 3 comments) Translations: Arabic, Chinese (Simplified) 1, Chinese (Simplified) 2, French 1, French 2, Japanese, Korean, Persian, Russian, Spanish 1, Spanish 2, Vietnames
jalammar.github.io
'AI 서비스 구축 스터디 > 모델 조사' 카테고리의 다른 글
| Whisper (0) | 2023.04.03 |
|---|---|
| ChatGPT (0) | 2023.04.03 |
| Naver Clova (0) | 2023.04.03 |
| 간단한 AI 웹서비스 예제 (0) | 2023.04.03 |
| AI 모델 조사 시작 (0) | 2023.04.03 |



