반응형
인공지능 & 머신러닝 & 딥러닝 개요
인공지능
- 인공지능은 사람이 수행하는 지능적인 작업을 자동화하기 위한 연구 활동
- 일반적으로 컴퓨터 프로그램이 하는 일들은 입력되어 있는 로직을 바탕으로 동작하기에 단순한 작업들을 수행하기에는 뛰어난 반면, 더 나아가 사람의 말을 이해하거나 사람 얼굴을 인식하는 등의 작업들은 단순히 개발자가 짠 로직만으로는 성능이 많이 떨어짐
- 수많은 케이스가 입력되어도 정확도가 높은 결과를 제시하기 위해선 사람의 뇌와 같이 지능적인 작업을 하는 도구가 필요함
머신러닝
- 현재 인공지능을 구현하기 위한 방식으로는 크게 규칙 기반 시스템(Rule-based system)과 머신러닝 2가지로 나뉨
- 규칙 기반 시스템: Rule(규칙)을 미리 프로그래머가 작성하는 방식
- 수많은 경우의 수에 대응하는 데는 한계가 명확하므로 세계관이 좁은 문제를 해결 할 때 사용됨
- 대표적으로 체스게임(바둑에 비해 단순), 게임 캐릭터의 활동 등
- 머신러닝: 프로그래머가 만든 모델을 바탕으로 들어오는 데이터를 학습하고 분석
- 모델 안에는 다양한 알고리즘이 적용되어 있고 학습할 수 있는 로직이 들어가 있음
- 세계관이 넓고 문제가 다양한 경우에는 사람처럼 학습을 해야 더 높은 정확도의 결과를 도출할 수 있으므로컴퓨터가 직접 학습할 수 있는 머신러닝(Machine Learning)이 각광받음
- 규칙 기반 시스템: Rule(규칙)을 미리 프로그래머가 작성하는 방식
딥러닝
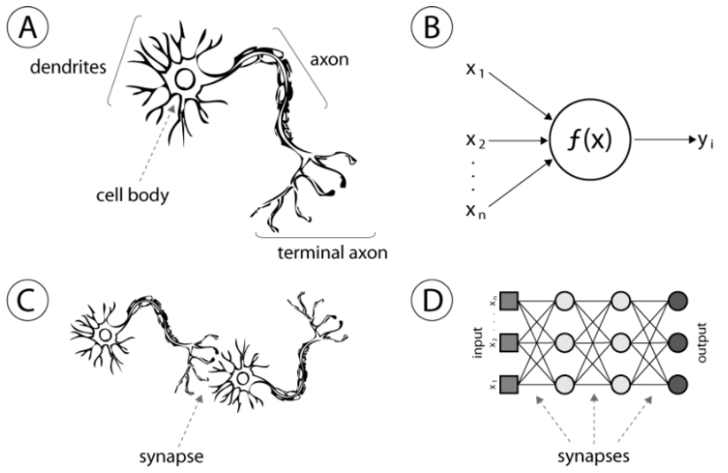
- 인공 신경망: 효율이 높은 머신러닝을 구현하기 위해 여러 가지 알고리즘을 연구하던 중 인간의 뇌 구조(뉴런의 연결)에 영감을 받아 만들어낸 알고리즘
- 현재 대부분의 머신러닝 알고리즘은 '인공 신경망' 알고리즘을 사용
- 인공 신경망 기술의 핵심은 층층이 들어있는 노드(뉴런 역할)
- 입력 값을 인공 신경망 모델에 넣으면 순차적으로 노드들을 타면서 수치가 계산되고 최종적으로 결과 값을 반환
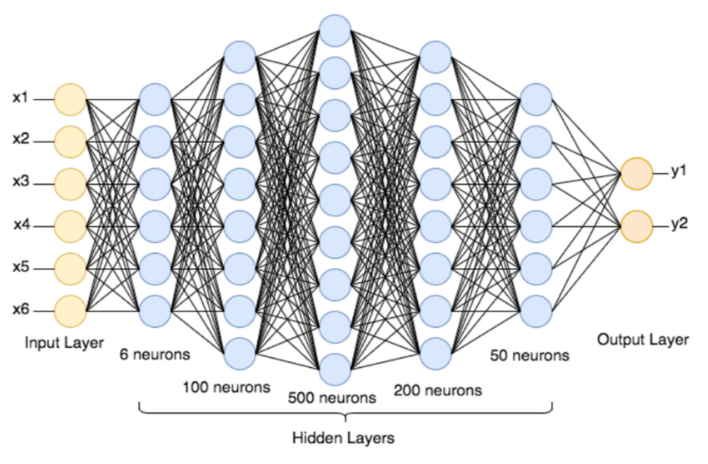
- 딥러닝: '인공 신경망' 기술을 기반으로 수많은 연산을 통해 더 정확한 결과를 예측하는 모델
- 노드(정확히는 은닉층)를 훨씬 많이 사용해서 깊은(Deep) 인공 신경망 모델을 사용한 방식
- 컴퓨터 하드웨어 성능이 급성장하며 더 많은 계산과 학습이 가능해졌고, 자연스럽게 인공 신경망의 깊이가 깊어질 수 있었음
- 최근 우리가 접하는 기사 중 대부분의 머신러닝 기술은 딥러닝 모델을 기반으로 함
- 구글에서 만든 '티처블 머신' 서비스는 누구나 무료로 머신러닝 모델을 만들 수 있도록 쉬운 UI와 기능을 제공
AI 트렌드
초기 딥러닝 모델
- 딥러닝은 기본적으로 학습을 위해 수많은 데이터를 필요로 함
- 학습용 데이터를 수집하고 분류(라벨링)하는 것이 학습을 위해 가장 중요
- 수많은 데이터를 넣어서 학습이 된 이후에야 실제 상황의 데이터가 들어왔을 때 학습된 모델이 올바른 값을 내려줄 수 있기 때문
- 학습 데이터를 바탕으로 정의된 문제에는 강점을 보이지만 다른 범주의 문제는 잘 해결하지 못 한다는 문제점 존재
- 사람 얼굴을 인식하는 딥러닝 모델은 고양이 얼굴을 인식할 때는 낮은 정확도를 보임
- 즉 수많은 사람 얼굴 사진을 수집해서 학습시킨 모델은 고양이 인식에는 쓸모가 없음
- 그래서 초기에는 조금씩 다른 유형의 모델을 만들려면 데이터를 전부 새로 수집해야 하는 번거로움이 존재하였음
Transfer Learning (전이 학습)
- 전이 학습(Transfer Learning): 기존의 학습된 모델을 일부 변형해서 학습시키는 것
- 과거처럼 전부 다시 학습 시킬 필요 x
- 사람 얼굴을 인식하는 모델에서 조금만 고양이 얼굴 관련된 학습을 시키면 고양이도 인식할 수 있음
- 대표적인 전이 학습 방식으로 파인 튜닝(Fine Tuning)
- 파인 튜닝: 기존에 보유한 데이터로 학습을 한 번 시킨 후 진짜 필요한 학습 데이터 일부로 새롭게 학습시키는 기술
- 적은 데이터로도 높은 성능을 낼 수 있음
- 기존에 있는 데이터들을 잘 활용하면 새롭게 학습할 데이터가 많이 없어도 됨
- 대표적인 전이학습 모델로 텍스트 기반 모델인 GPT-2, 이미지 기반 모델인 GAN 등이 있음
- GAN 모델은 딥페이크의 기반 모델
Few Shot Learning
- 파인튜닝 기술을 적용하더라도 많은 데이터를 필요로 함
- 더 적은 데이터로도 정확도가 높은 모델 필요
- 고양이 사진을 한 번 보고도 수많은 다른 고양이 사진들에 고양이가 있다는 것을 알기 위함
- 퓨삿 러닝(Few Shot Learning): 적은 데이터로도 학습이 가능하게 하는 방식
- 이를 가능하게 하기 위해선 적은 데이터를 바탕으로 유사한 데이터를 생성하거나 고차원의 학습 데이터들(ex. 이미지)을 저차원(ex. 숫자)으로 변환해서 특징을 잡아내는 기술 등을 필요
- 현재 퓨샷 러닝에 관해 활발한 연구가 진행되고 있어 나중에는 적은 데이터만으로 높은 성능을 내는 모델이 만들어질 것이라고 전문가들은 예측
- 퓨샷 러닝이 적용된 기술 대표적인 기술 GPT-3가 있음
Reference
https://www.inflearn.com/course/it-%EA%B0%9C%EB%B0%9C%EC%A7%80%EC%8B%9D#
IT 회사에서 비개발자가 살아남기 위한 모든 개발 지식 A to Z - 인프런 | 강의
본 강의는 멤버십 구독 개념으로 한 번 구매하면 계속 추가되는 수업도 수강할 수 있습니다😃, [사진] 이 강의는! 단순히 개발 용어만을 알려주지 않습니다.IT 회사에서 개발자들이 실제로 하
www.inflearn.com
https://www.grabbing.me/IT-A-to-Z-By-1e1fbc981b7c4c03ac44943085ac8304
[IT 개발자와 일할 때 필요한 모든 개발지식] A to Z 자료 모음집 By 그랩
장담하건대 이 내용들만 알고 계시면 IT 개발의 전체적인 흐름은 전부 파악한다고 보셔도 무방합니다.
www.grabbing.me
반응형
'비개발자의 개발 지식 스터디 > 데이터' 카테고리의 다른 글
| 그로스 해킹 (0) | 2023.07.26 |
|---|---|
| 데이터 직군 (0) | 2023.07.26 |
| 데이터의 전체 프로세스 (0) | 2023.07.26 |


