BERT
BERT는 2018년 구글이 공개한 사전 학습된 모델이다.

BERT는 트랜스포머를 이용하여 구현되었으며, 위키피디아(25억 단어)와 BooksCorpus(8억 단어) 같은 레이블이 없는 텍스트 데이터로 사전 훈련된 언어 모델이다.
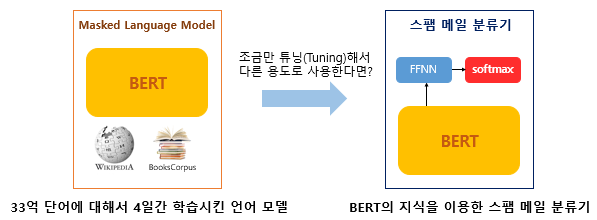
BERT가 높은 성능을 얻을 수 있는 것은 레이블이 없는 방대한 데이터로 사전 훈련된 모델로 레이블이 있는 다른 작업(Task)에서 추가 훈련과 함께 하이퍼파라미터를 재조정하여 성능이 높게 나오는 기존의 사례들을 참고하였기 때문이다.
다른 작업에 대해서 파라미터 재조정을 위한 추가 훈련 과정을 파인 튜닝(Fine-tuning)이라고 한다.
BERT 학습 과정
1. 단어들을 임베딩한다. (input layer)

- Token Embedding : 각 문자 단위로 임베딩
- Segment Embedding : 토큰화 한 단어들을 다시 하나의 문장으로 만드는 작업
- Position Embedding : 토큰의 상대적인 위치를 고려한 인코딩
Token Embedding에서 단어보다 더 작은 단위로 쪼개는 서브워드 토크나이저 WordPiece를 사용한다.

2. 단어들을 임베딩하여 인코딩 후, MLM과 NSP 방식을 사용하여 모델을 학습한다. (Pre-Training)

- MLM(Masked Language Model): 입력 문장에서 임의로 토큰을 버리고 그 토큰을 맞추는 방식으로 학습 진행
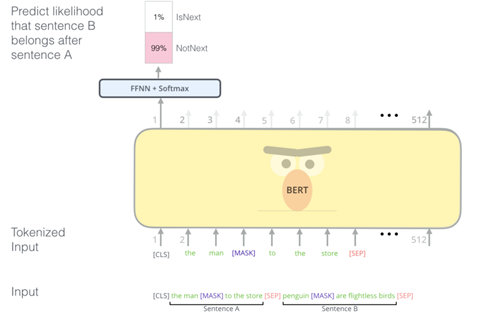
- NSP(Next Sentence Prediction): 두 문장을 주고 순서를 예측하는 방식으로 문장 간 관련성을 고려하며 학습 진행
3. 사전 학습 모델을 특정 태스크의 레이블이 있는 데이터로 추가 훈련한다. (Transfer Learning)
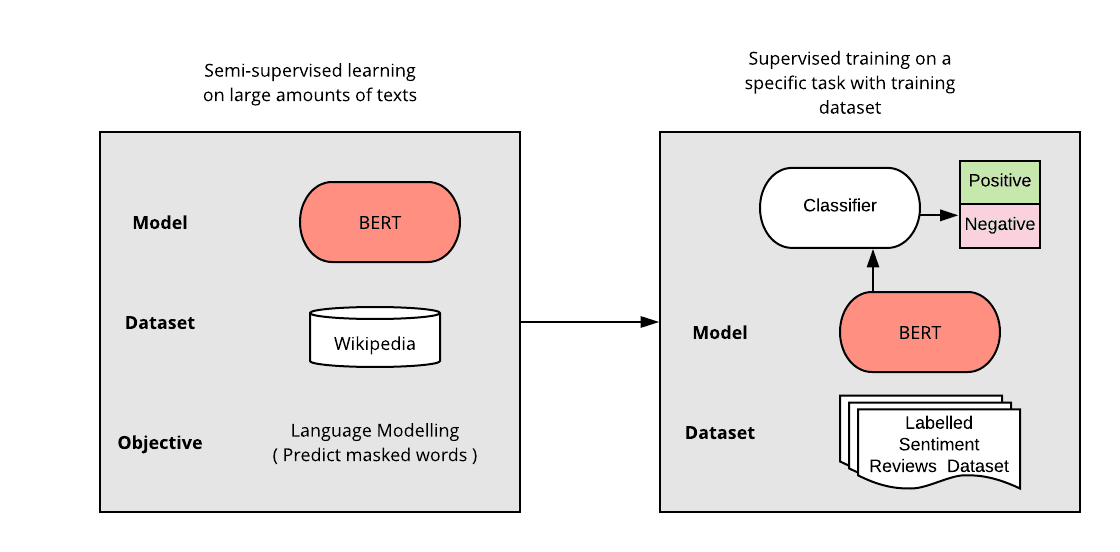
BERT 활용법
1. 문서 분류 (문장 벡터 활용)
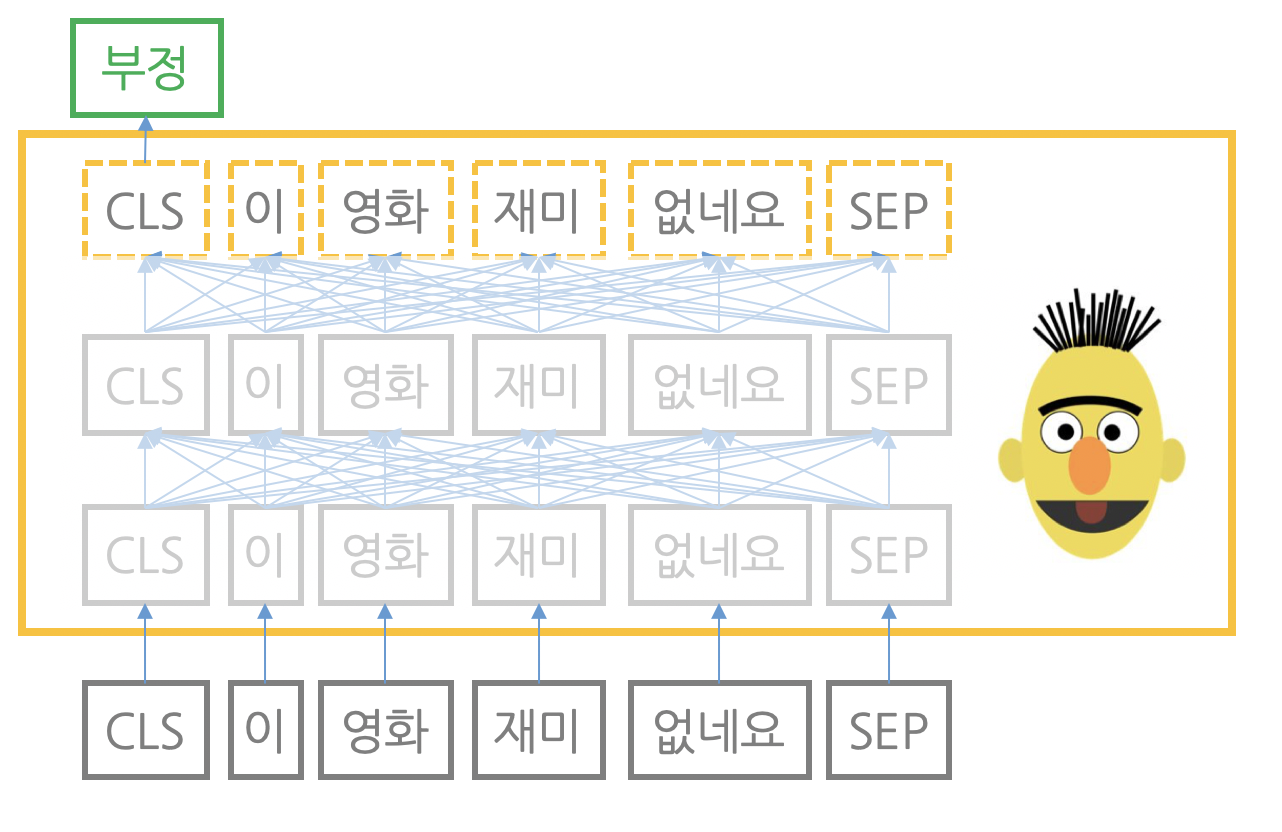
- 문장을 워드피스(wordpiece)로 토큰화한 뒤 앞뒤에 문장 시작과 끝을 알리는 스페셜 토큰 CLS와 SEP를 각각 추가한 뒤 BERT에 입력한다.
- BERT 모델 마지막 블록(레이어)의 벡터 중 CLS에 해당하는 벡터를 추출한다.(CLS벡터 : 문장 전체 의미가 벡터 하나로 응집)
- CLS 벡터에 작은 모듈을 하나 추가해, 그 출력이 미리 정해 놓은 범주(긍정, 중립, 부정)가 될 확률을 구한다.
2. 개체명 인식 (단어 벡터 활용)

- 마지막 블록의 모든 단어 벡터를 활용한다.
- BERT 모델 마지막 블록(레이어)의 출력은 문장 내 모든 단어에 해당하는 벡터들의 시퀀스이다.
- 이렇게 뽑은 단어 벡터들 위에 작은 모듈을 각각 추가해, 그 출력이 각 개체명 범주(기관명, 지명 등)가 될 확률을 구한다.
BERT 한계점
일반 NLP 모델에서는 잘 작동하지만, 특정 분야(과학, 금융 등)의 언어 모델에서는 성능이 좋지 않다고 알려져 있다.
이는 사용 단어들이 다르고 언어의 특성이 다르기 때문인데, 특정 분야의 BERT 성능 개선을 위해서는 그 분야의 언어 데이터를 수집하고 추가로 학습해줘야 한다.
BERT와 GPT의 차이점

Reference
17-02 버트(Bidirectional Encoder Representations from Transformers, BERT)
* 트랜스포머 챕터에 대한 사전 이해가 필요합니다.  BERT(Bidire…
wikidocs.net
'AI 서비스 구축 스터디 > 모델 조사' 카테고리의 다른 글
| YOLO (0) | 2023.04.04 |
|---|---|
| GAN (0) | 2023.04.03 |
| Whisper (0) | 2023.04.03 |
| ChatGPT (0) | 2023.04.03 |
| Transformer (0) | 2023.04.03 |



