Object Detection (객체 탐지)
객체 탐지는 컴퓨터 비전, 이미지 처리와 관련된 컴퓨터 기술로 디지털 이미지와 비디오로 특정한 계열의 시맨틱 객체 인스턴스를 감지하는 일을 다룬다.


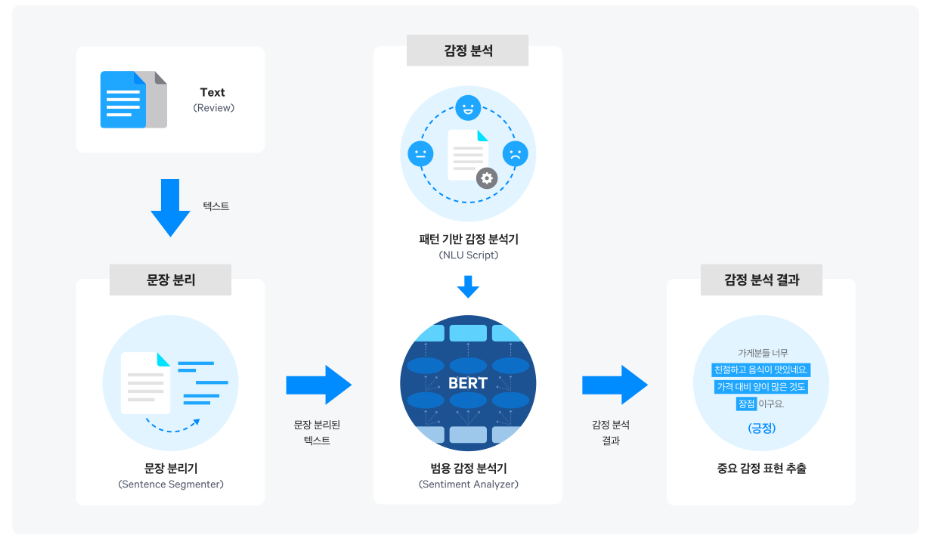
YOLO란
CNN 기반 대표적인 단일 단계 방식의 객체 탐지 알고리즘(고정된 사이즈의 그리드 영역으로 크기가 미리 결정된 객체 식별)이다.
YOLO의 특징은 다음과 같다.
- 실시간 객체 탐지
- 객체들의 위치를 한번만 보고 예측
- 미리 지정된 경계박스(Bounding Box)의 개수를 예측하고 신뢰도를 계산
- 높은 신뢰도를 가지는 객체의 위치를 찾아 카테고리를 파악
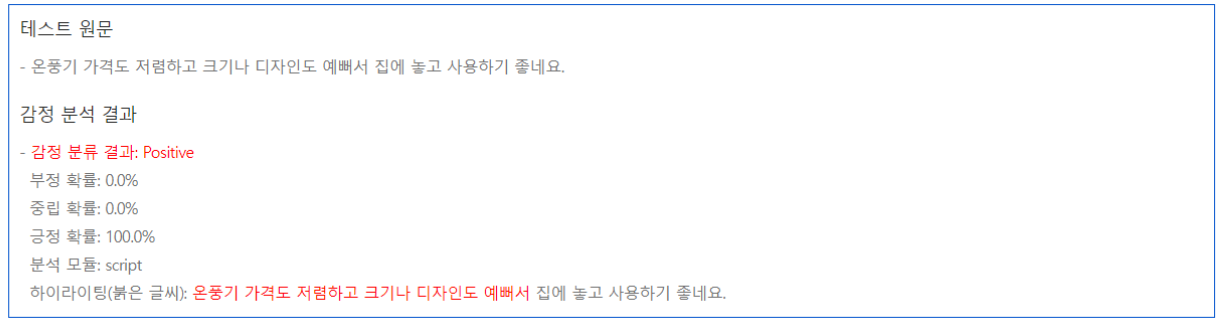
YOLO 작동 방법
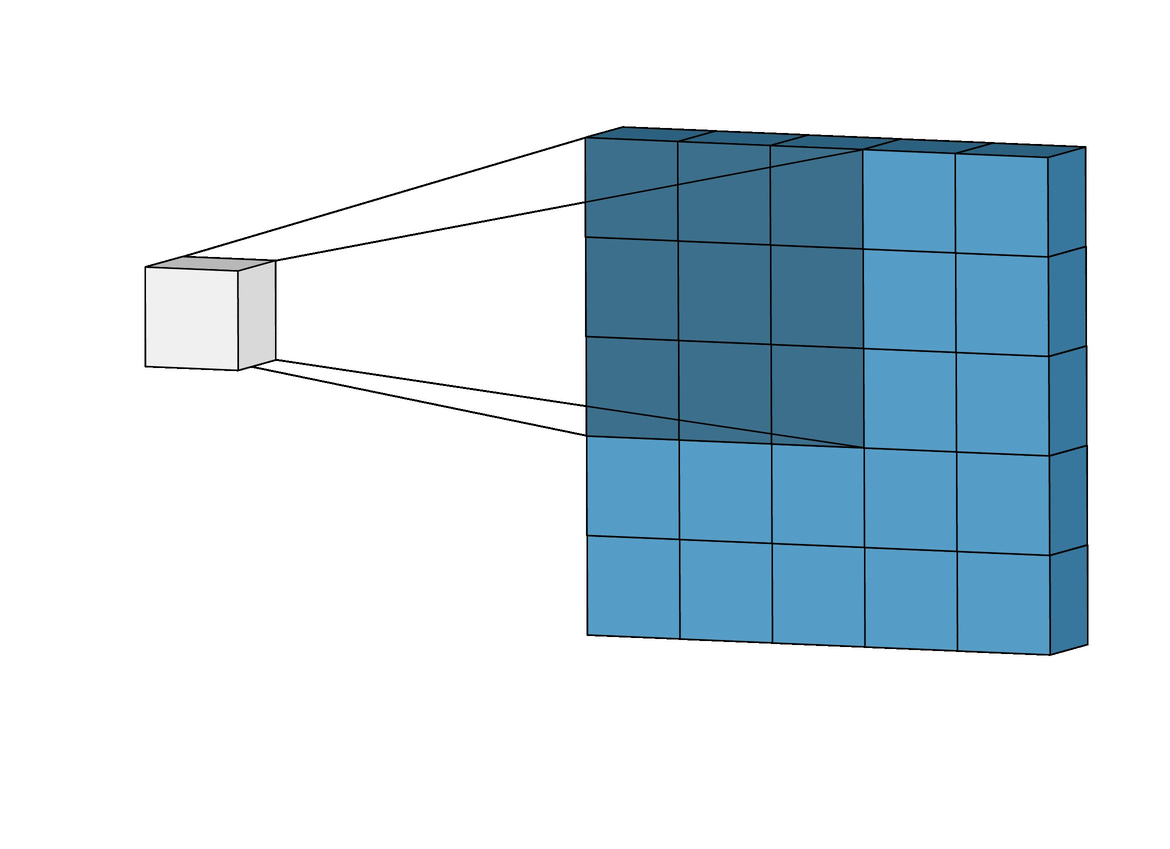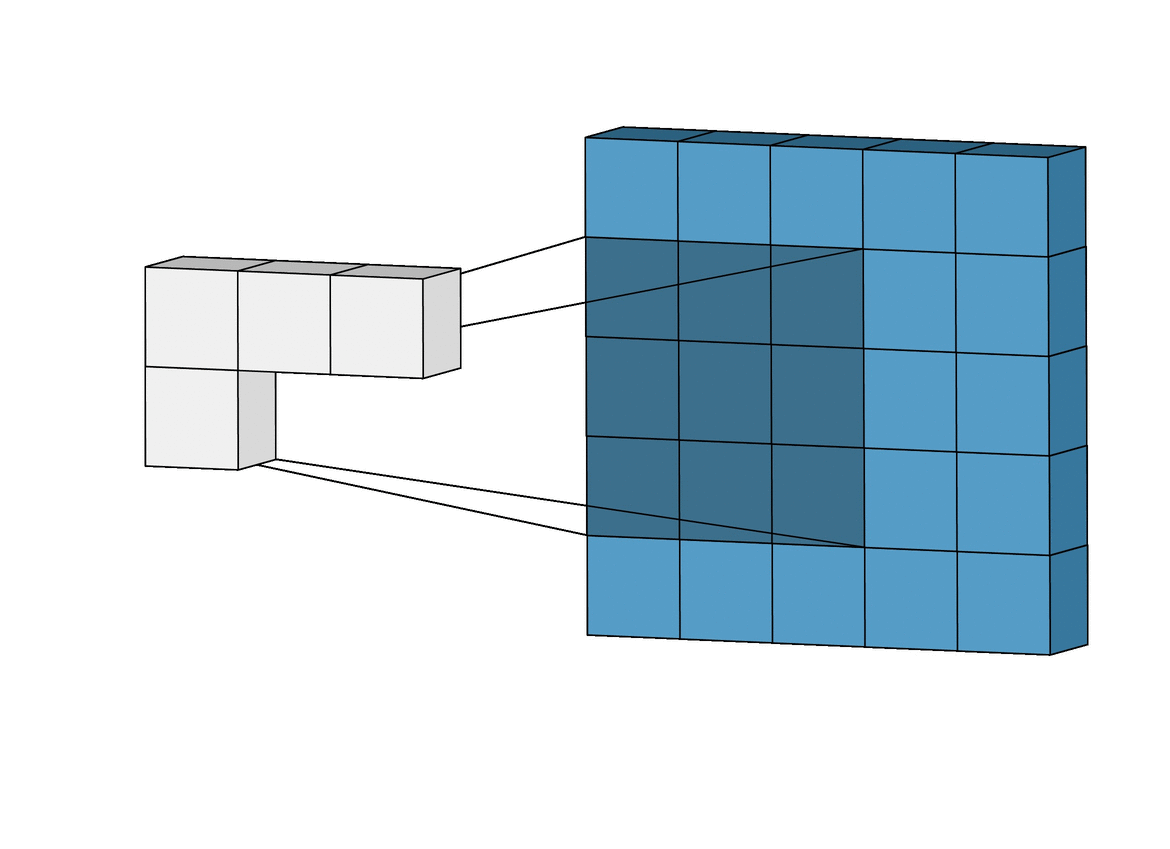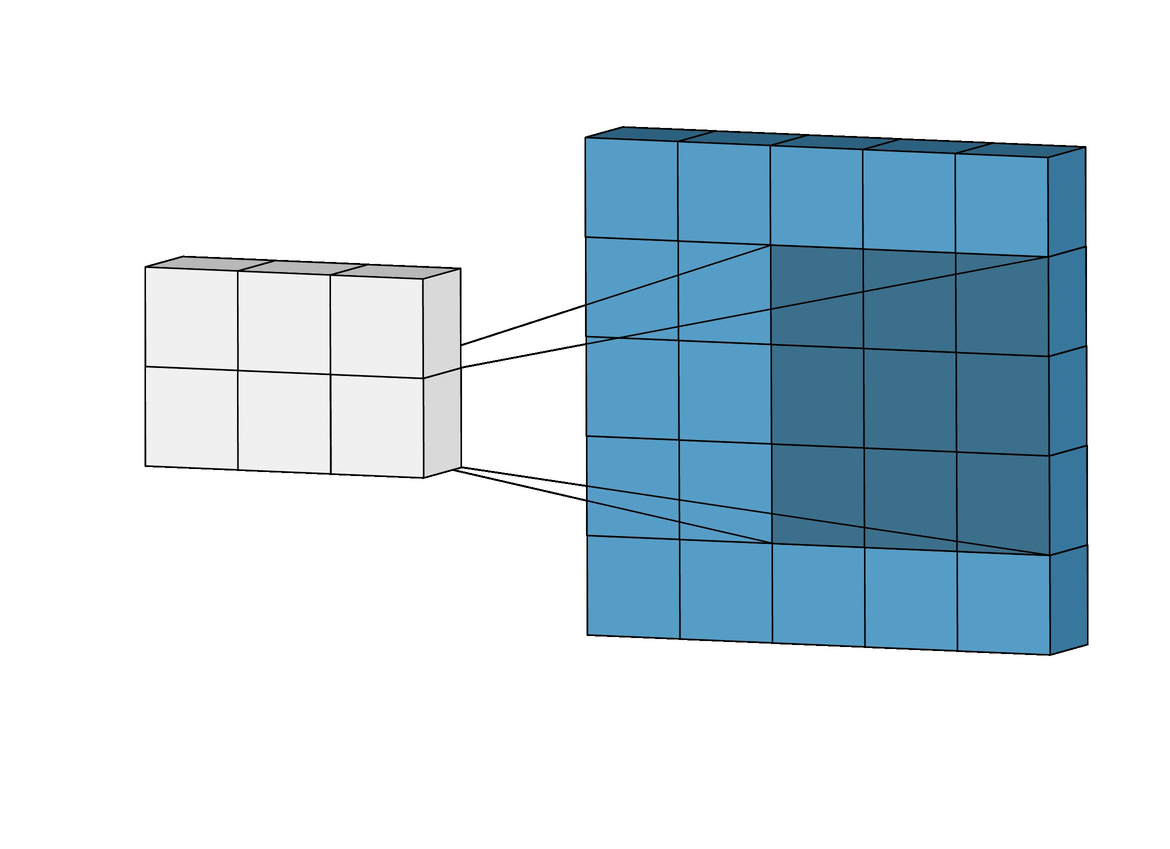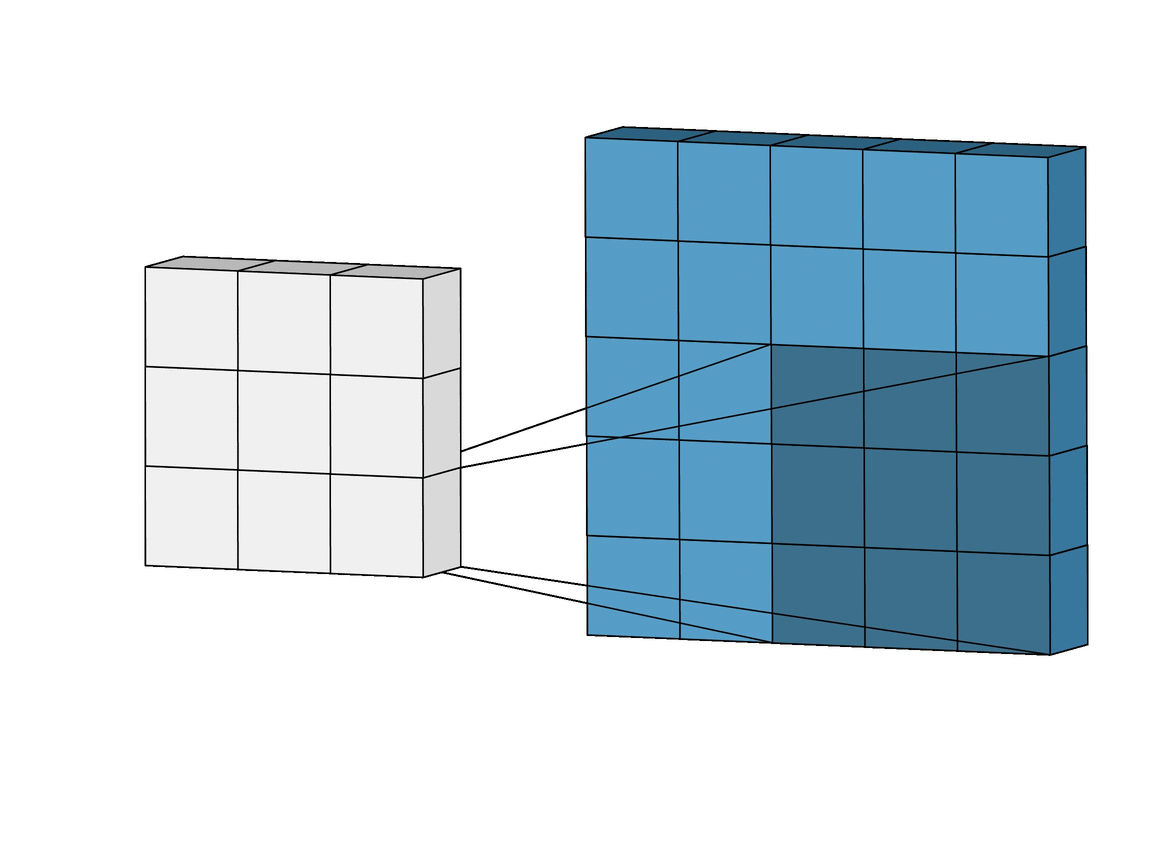
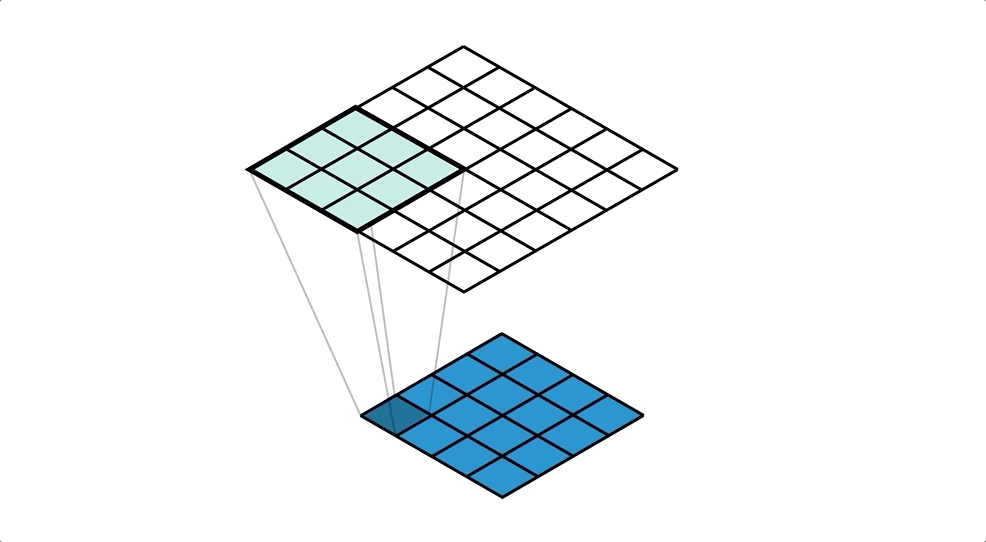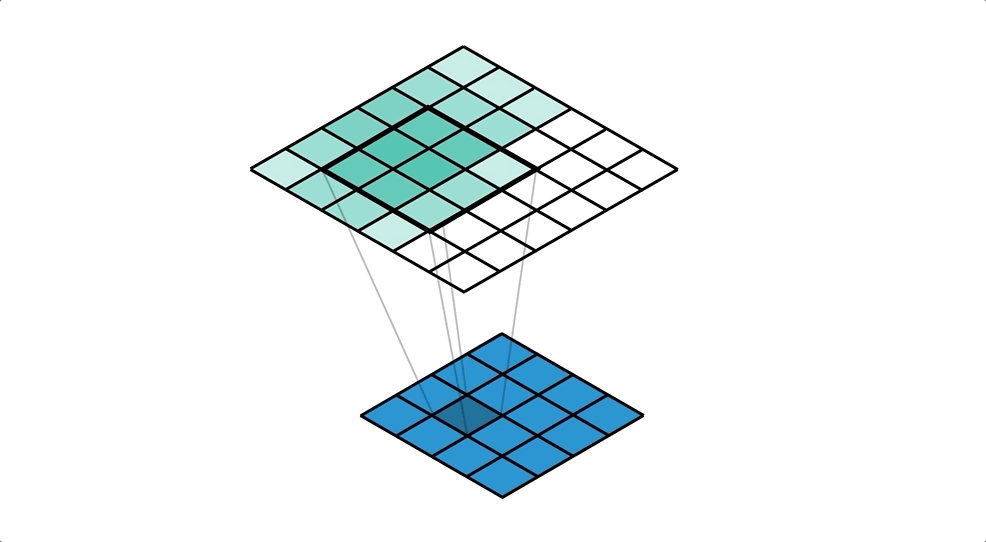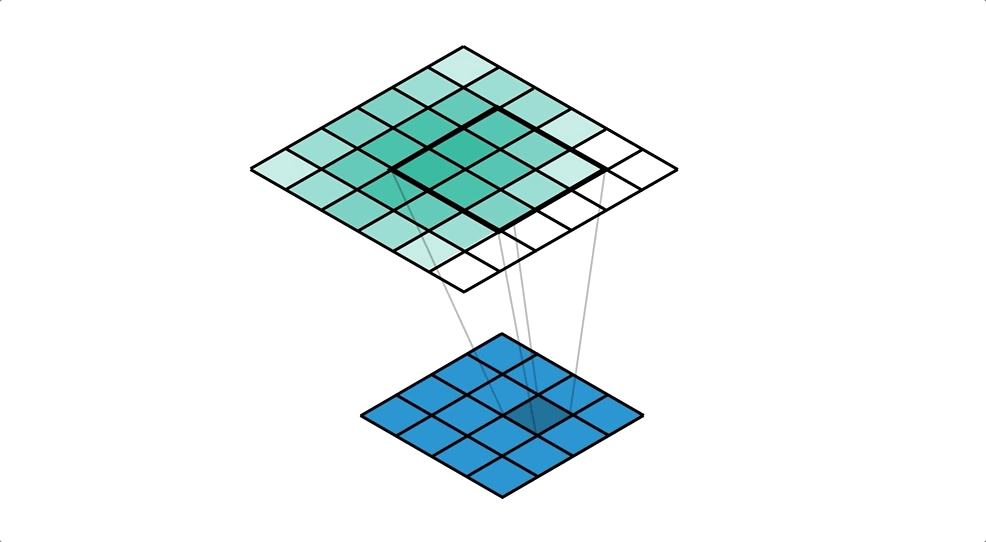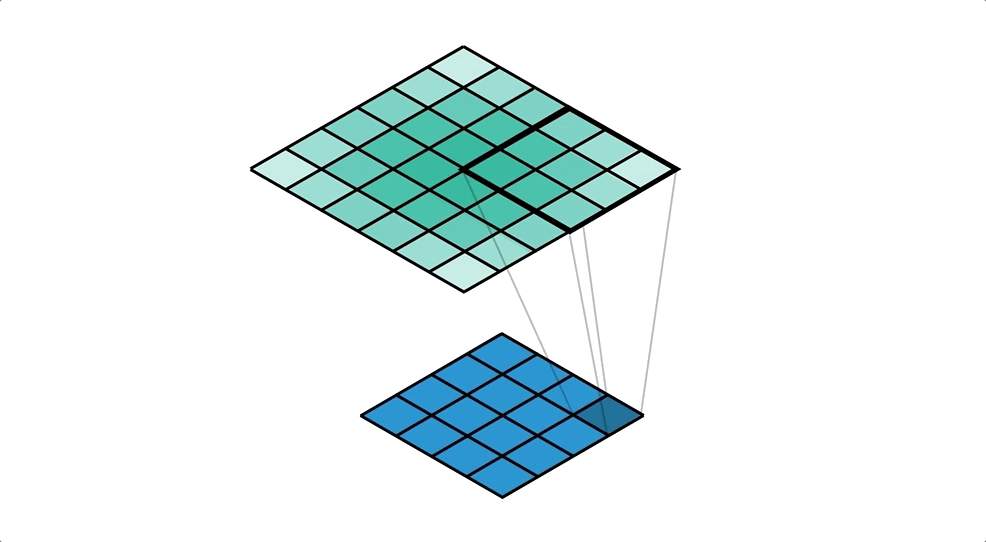
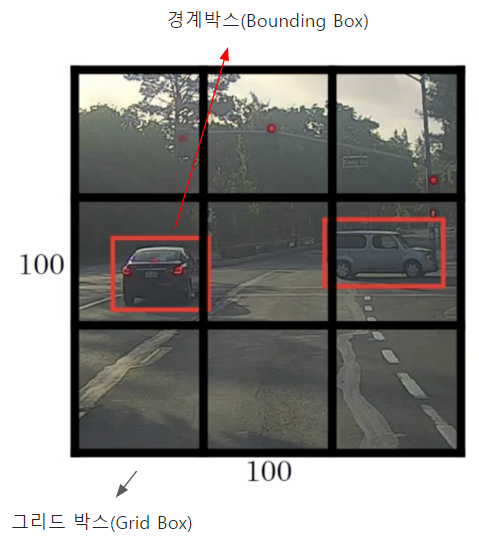
객체 탐지 역할의 그리드 박스(Grid Box)와, 객체 정보를 담고 있는 경계 박스(Bounding Box)를 이용하여 객체를 식별한다.

- 그리드 박스(Grid Box): 이미지를 구역으로 나눈 것으로 각 그리드의 중앙으로 부터 객체를 탐지하는 역할
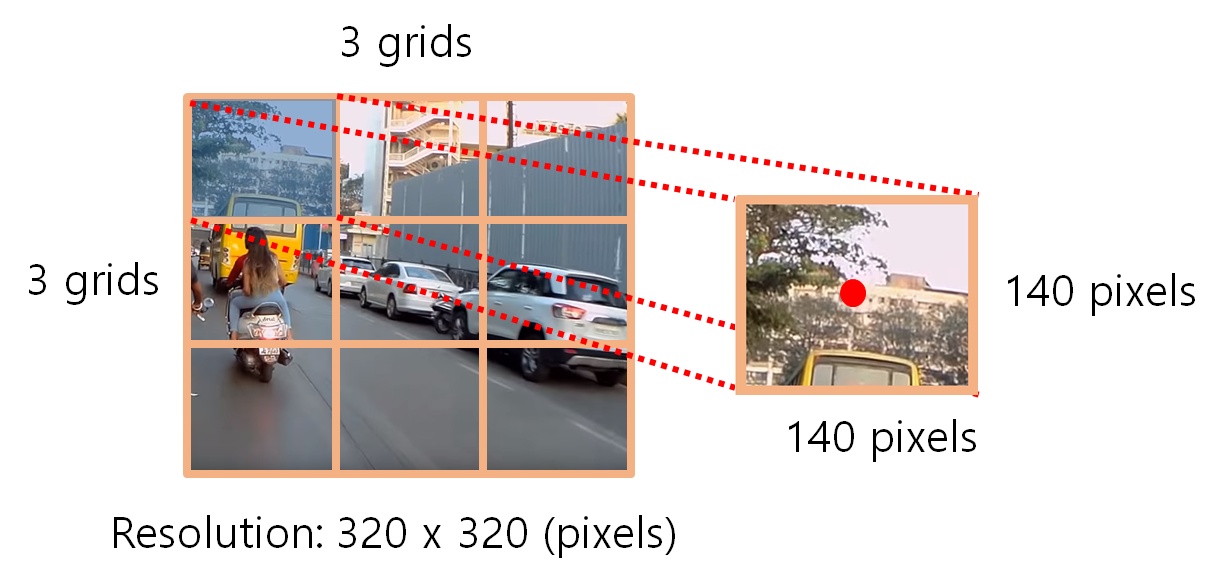
- 경계 박스(Bounding Box): 물체의 위치에 대한 좌표와 가로·세로 크기, 신뢰도의 수치를 포함

위와 같이 입력 이미지(Training Data)를 그리드로 나누고, 각 그리드와 미리 정의된 경계 박스(Bounding Box)에 대해 다음 정보들을 가지고 모델을 학습한다.
- 그리드 박스의 중심
- 상자의 높이와 너비
- 객체를 포함하고 있을 확률
- 객체의 클래스(분류 라벨)
Reference
YOLO로 이해하는 이미지 객체 감지(2) - YOLO의 역사
지난 글에서 우리들은 컴퓨터 비전(Computer Vision)에서의 객체 감지(Objection Detection)의 발전 과정과 이를 이해하기 위한 기계학습 및 인공신경망의 개념에 대해 살펴 보았습니다. 본 글에서는 전체
eair.tistory.com
https://wooono.tistory.com/238
[DL] Object Detection (Sliding Windows, YOLO)
Object Detection에는 여러가지 Algorithm이 존재합니다. Sliding Windows Detection YOLO Detection 하나하나 다뤄보겠습니다. Sliding Windows Detection 자동차 감지 알고리즘을 만들고 싶다고 가정해봅시다. 그렇다면,
wooono.tistory.com
'AI 서비스 구축 스터디 > 모델 조사' 카테고리의 다른 글
| BERT (0) | 2023.04.04 |
|---|---|
| GAN (0) | 2023.04.03 |
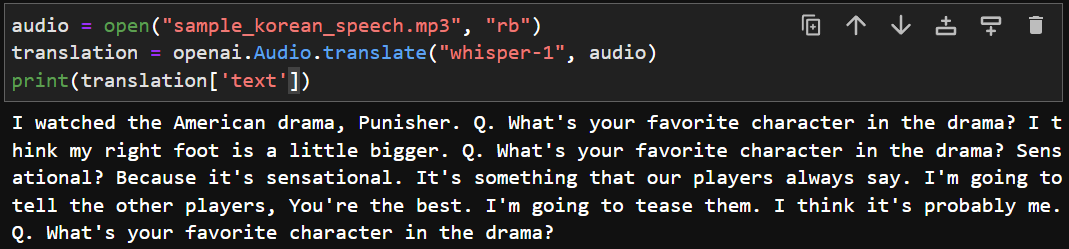
| Whisper (0) | 2023.04.03 |
| ChatGPT (0) | 2023.04.03 |
| Transformer (0) | 2023.04.03 |